
Big Brands? Google Brand Promotion: New Search Engine Rankings Place Heavy Emphasis on Branding

Originally
when we published this we were going to make it subscriber only
content, but the change is so important that I thought we should share
some of it with the entire SEO industry. This post starts off with a
brief history of recent algorithm updates, and shows the enormous weight
Google is placing on branded search results.
The Google Florida Update
I got started in the search field in 2003, and one of the things that helped get my name on the map was when I wrote about the November 14th Google Florida update in a cheeky article titled Google Sells Christmas [1]. To this day many are not certain exactly what Google changed back then, but the algorithm update seemed to hit a lot of low level SEO techniques. Many pages that exhibited the following characteristics simply disappeared from the search results
Google Austin, Other Filters/Penalties/Updates/etc.
In the years since Google has worked on creating other filters and penalties. At one point they tried to stop artificial anchor text manipulation so much that they accidentally filtered out some brands for their official names [2].
The algorithms have got so complex on some fronts that Google engineers do not even know about some of the filters/penalties/bugs (the difference between the 3 labels often being an issue of semantics). In December 2007, a lot of pages that ranked #1 suddenly ended up ranking no better than position #6 [3] for their core target keyword (and many related keywords). When questioned about this, Matt Cutts denied the problem until after he said they had already fixed it. [4]
Google helped change the structure of the web in January 2005 when they proposed a link rel=nofollow tag [5]. Originally it was said to stop blog spam, but by September of the same year, Matt Cutts changed his tune to where you were considered a spammer if you were buying links without using rel=nofollow on them. Matt Cutts documented some of his repeated warnings on the Google Webmaster Central blog. [6]
A bunch of allegedly "social" websites have adopted the use of the nofollow tag, [7] turning their users into digital share-croppers [8] and eroding the link value [9] that came as a part of being a well known publisher who created link-worthy content.
In May of 2007 Google rolled out Universal search [10], which mixes in select content from vertical search databases directly into the organic search results. This promoted
Tracking Users Limits Need for "Random" Walk
The PageRank model is an algorithm built on a random walk of links on the web graph. But if you have enough usage data, you may not need to base your view of the web on that perspective since you can use actual surfing data to help influence the search results. Microsoft has done research on this concept, under the name of BrowseRank. [13] In Internet Explorer 8 usage data is sent to Microsoft by default.
Google's Chrome browser phones home [14] and Google also has the ability to track people (and how they interact with content) through Google Accounts, Google Analytics, Google AdSense, DoubleClick, Google AdWords, Google Reader, iGoogle, Feedburner, and Youtube.
Yesterday we launched a well received linkbait, and the same day our rankings for our most valuable keywords were lifted in both Live and Google, part of that may have been the new links, but I would be willing to bet some of it was caused from 10,000's of users finding their way to our site.
Google's Eric Schmidt Offers Great SEO Advice
If you ask Matt Cutts what big SEO changes are coming up he will tell you "make great content" and so on...never wanting to reveal the weaknesses of their search algorithms. Eric Schmidt, on the other hand, is frequently talking to media and investors with intent of pushing Google's agendas and all the exciting stuff that is coming out. In the last 6 months Mr. Schmidt has made a couple quotes that smart SEOs should incorporate into their optimization strategies - one on brands [15], and another on word relationships [16].
Here is Mr. Schmidt's take on brands from last October
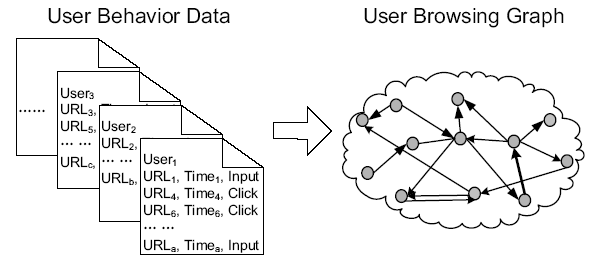
Tools like RankPulse [17] allow you to track the day to day Google ranking changes for many keywords.
4 airlines recently began ranking for "airline tickets"
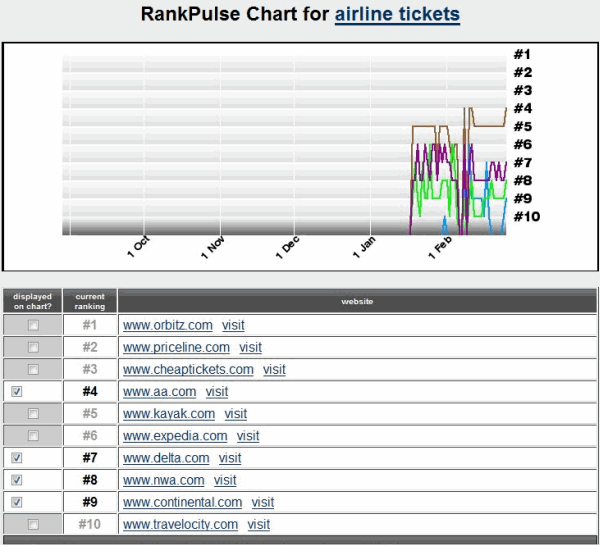 At least 90% of the first page of search results for auto insurance is owned by large national brands.
At least 90% of the first page of search results for auto insurance is owned by large national brands.
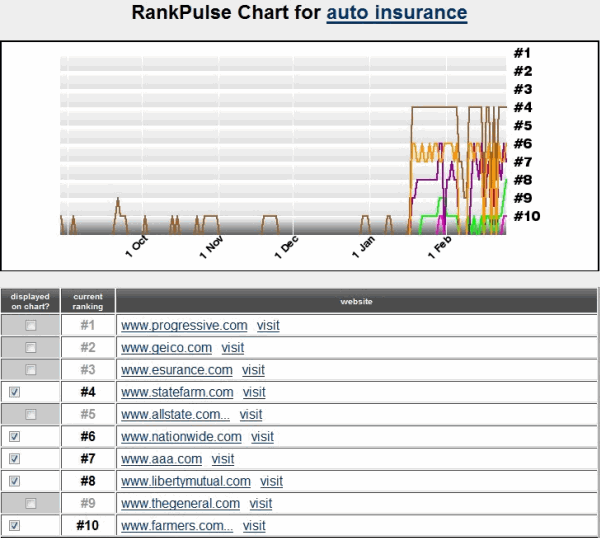 3 boot brands / manufacturers rose from nowhere to ranking at the top of the search results.
3 boot brands / manufacturers rose from nowhere to ranking at the top of the search results.
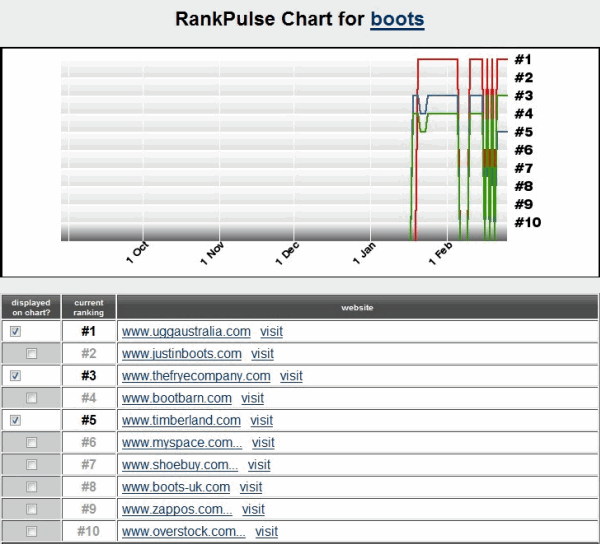 3 of the most well recognized diet programs began ranking for diets.
3 of the most well recognized diet programs began ranking for diets.
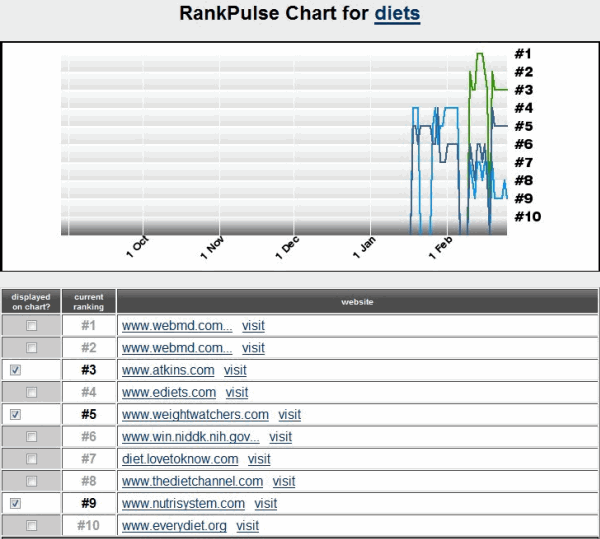 4 multi-billion dollar health insurance providers just began ranking, with Aetna bouncing between positions #1 and 2.
4 multi-billion dollar health insurance providers just began ranking, with Aetna bouncing between positions #1 and 2.
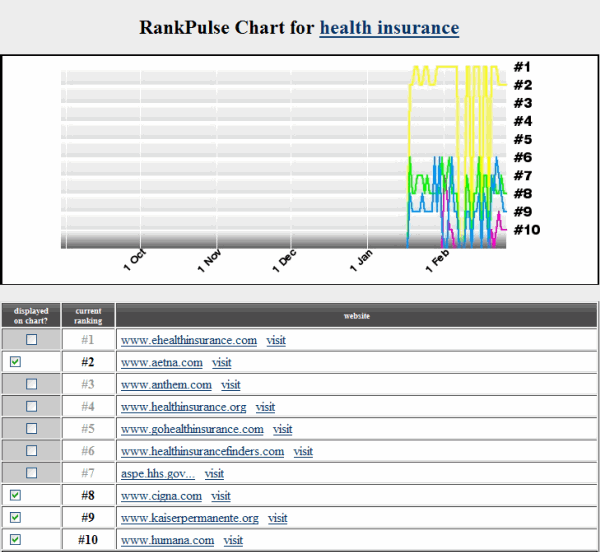 3 of the largest online education providers began ranking for online degree.
3 of the largest online education providers began ranking for online degree.
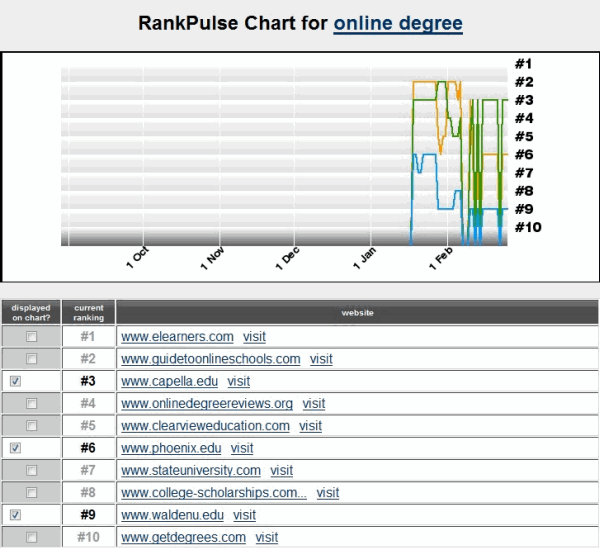 5 watch brands jumped onto the first page of search results for watches. To be honest I have never heard of Nixon Now.
5 watch brands jumped onto the first page of search results for watches. To be honest I have never heard of Nixon Now.
The above images are just some examples. Radioshack.com recently started ranking for electronics and Hallmark.com just recently started ranking for gifts. The illustrations do not list all brands that are ranking, but brands that just started ranking. Add in other brands that were already ranking, and in some cases brands have 80% or 90% of the first page search results for some of the most valuable keywords. There are thousands of other such examples across all industries if you take the time to do the research, but the trend is clear - Google is promoting brands for big money core category keywords.
Want to read the rest of our analysis? If you are a subscriber you can access it here.
The Google Florida Update
I got started in the search field in 2003, and one of the things that helped get my name on the map was when I wrote about the November 14th Google Florida update in a cheeky article titled Google Sells Christmas [1]. To this day many are not certain exactly what Google changed back then, but the algorithm update seemed to hit a lot of low level SEO techniques. Many pages that exhibited the following characteristics simply disappeared from the search results
- repetitive inbound anchor text with little diversity
- heavy repetition of the keyword phrase in the page title and on the page
- words is a phrase exhibiting close proximity with few occurrences of the keywords spread apart
- a lack of related/supporting vocabulary in the page copy
Google Austin, Other Filters/Penalties/Updates/etc.
In the years since Google has worked on creating other filters and penalties. At one point they tried to stop artificial anchor text manipulation so much that they accidentally filtered out some brands for their official names [2].
The algorithms have got so complex on some fronts that Google engineers do not even know about some of the filters/penalties/bugs (the difference between the 3 labels often being an issue of semantics). In December 2007, a lot of pages that ranked #1 suddenly ended up ranking no better than position #6 [3] for their core target keyword (and many related keywords). When questioned about this, Matt Cutts denied the problem until after he said they had already fixed it. [4]
When Barry asked me about "position 6" in late December, I said that I didn't know of anything that would cause that. But about a week or so after that, my attention was brought to something that could exhibit that behavior. We're in the process of changing the behavior; I think the change is live at some datacenters already and will be live at most data centers in the next few weeks.Recent Structural Changes to the Search Results
Google helped change the structure of the web in January 2005 when they proposed a link rel=nofollow tag [5]. Originally it was said to stop blog spam, but by September of the same year, Matt Cutts changed his tune to where you were considered a spammer if you were buying links without using rel=nofollow on them. Matt Cutts documented some of his repeated warnings on the Google Webmaster Central blog. [6]
A bunch of allegedly "social" websites have adopted the use of the nofollow tag, [7] turning their users into digital share-croppers [8] and eroding the link value [9] that came as a part of being a well known publisher who created link-worthy content.
In May of 2007 Google rolled out Universal search [10], which mixes in select content from vertical search databases directly into the organic search results. This promoted
- Google News
- Youtube videos (and other video content)
- Google Product Search
- Google Maps/Local
- select other Google verticals, like Google Books
Tracking Users Limits Need for "Random" Walk
The PageRank model is an algorithm built on a random walk of links on the web graph. But if you have enough usage data, you may not need to base your view of the web on that perspective since you can use actual surfing data to help influence the search results. Microsoft has done research on this concept, under the name of BrowseRank. [13] In Internet Explorer 8 usage data is sent to Microsoft by default.
Google's Chrome browser phones home [14] and Google also has the ability to track people (and how they interact with content) through Google Accounts, Google Analytics, Google AdSense, DoubleClick, Google AdWords, Google Reader, iGoogle, Feedburner, and Youtube.
Yesterday we launched a well received linkbait, and the same day our rankings for our most valuable keywords were lifted in both Live and Google, part of that may have been the new links, but I would be willing to bet some of it was caused from 10,000's of users finding their way to our site.
Google's Eric Schmidt Offers Great SEO Advice
If you ask Matt Cutts what big SEO changes are coming up he will tell you "make great content" and so on...never wanting to reveal the weaknesses of their search algorithms. Eric Schmidt, on the other hand, is frequently talking to media and investors with intent of pushing Google's agendas and all the exciting stuff that is coming out. In the last 6 months Mr. Schmidt has made a couple quotes that smart SEOs should incorporate into their optimization strategies - one on brands [15], and another on word relationships [16].
Here is Mr. Schmidt's take on brands from last October
The internet is fast becoming a "cesspool" where false information thrives, Google CEO Eric Schmidt said yesterday. Speaking with an audience of magazine executives visiting the Google campus here as part of their annual industry conference, he said their brands were increasingly important signals that content can be trusted.And here is his take on word relationships from the most recent earnings call
"Brands are the solution, not the problem," Mr. Schmidt said. "Brands are how you sort out the cesspool."
"Brand affinity is clearly hard wired," he said. "It is so fundamental to human existence that it's not going away. It must have a genetic component."
“Wouldn’t it be nice if Google understood the meaning of your phrase rather than just the words that are in that phrase? We have a lot of discoveries in that area that are going to roll out in the next little while.”The January 18th Google Update Was Bigger Than Florida, but Few People Noticed it
Tools like RankPulse [17] allow you to track the day to day Google ranking changes for many keywords.
4 airlines recently began ranking for "airline tickets"
The above images are just some examples. Radioshack.com recently started ranking for electronics and Hallmark.com just recently started ranking for gifts. The illustrations do not list all brands that are ranking, but brands that just started ranking. Add in other brands that were already ranking, and in some cases brands have 80% or 90% of the first page search results for some of the most valuable keywords. There are thousands of other such examples across all industries if you take the time to do the research, but the trend is clear - Google is promoting brands for big money core category keywords.
Want to read the rest of our analysis? If you are a subscriber you can access it here.
Published: February 25, 2009
New to the site? Join for Free and get over $300 of free SEO software.


Once you set up your free account you can comment on our blog, and you are eligible to receive our search engine success SEO newsletter.
Source: http://www.seobook.com/google-branding
Google’s Vince Update Produces Big Brand Rankings; Google Calls It A Trust “Change”
Mar 5, 2009 at 9:27am ET by Barry Schwartz
About a week ago, SEOs and Webmasters began noticing a significant
change in how Google returned results for a certain set of keywords.
Many webmasters felt Google was giving “big brands” a push in the search
results. However, Matt Cutts of Google created a video that answered many questions about this “brand push.”Let me first take you back to last week when on February 20th, a WebmasterWorld thread was created based on some SEOs noticing this change in Google. I then covered the thread at the Search Engine Roundtable on February 23rd, summarizing some of the discussion in the thread. Aaron Wall followed up that post on February 25th, with statistical data to show significant changes in the search results, pointing to evidence behind this brand push. Then we saw dozens of blog posts, discussion forum threads and Twitters from SEOs and webmasters about Google changing their algorithm to give big brands a major push in the search results.
Matt Cutts addressed these concerns in a three and a half minute video, which I have embedded below. Matt Cutts said this change is not necessarily a Google “update,” but rather what he would call a “minor change.” In fact, Matt told us a Googler named Vince created this change and they call it the “Vince change” at Google. He said it is not really about pushing brands to the front of the Google results. It is more about factoring trust more into the algorithm for more generic queries. He said most searchers won’t notice and it does not impact the long tail queries, but for some queries, Google might be factoring in things like trust, quality, PageRank and other metrics that convey the importance and value of a page, into the ranking algorithm. I guess, big brands have earned more trust than smaller brands, which is noted by all the recent chatter in our industry.
Here is the video, listen to it yourself then feel free to chime in, in our detailed Sphinn thread:

Canonical URL Tag - The Most Important Advancement in SEO Practices Since Sitemaps
February 13th, 2009 - Posted by randfish
to
Technical SEO Issues
146
0
The
announcement from Yahoo!, Live & Google that they will be
supporting a new "canonical url tag" to help webmasters and site owners
eliminate self-created duplicate content in the index is, in my
opinion, the biggest change to SEO best practices since the emergence of
Sitemaps. It's rare that we cover search engine announcements or "news
items" here on SEOmoz, as this blog is devoted more towards tactics than
breaking headlines, but this certainly demands attention and requires
quick education.
How Does it Operate?
The tag is part of the HTML header on a web page, the same section you'd find the Title attribute and Meta Description tag. In fact, this tag isn't new, but like nofollow, simply uses a new rel parameter. For example:
<link rel="canonical" href="http://www.seomoz.org/blog" /> 
- Whereas a 301 redirect re-points all traffic (bots and human visitors), the Canonical URL tag is just for engines, meaning you can still separately track visitors to the unique URL versions.
- A 301 is a much stronger signal that multiple pages have a single, canonical source. While the engines are certainly planning to support this new tag and trust the intent of site owners, there will be limitations. Content analysis and other algorithmic metrics will be applied to ensure that a site owner hasn't mistakenly or manipulatively applied the tag, and we certainly expect to see mistaken use of the tag, resulting in the engines maintaining those separate URLs in their indices (meaning site owners would experience the same problems noted below).
- 301s carry cross-domain functionality, meaning you can redirect a page at domain1.com to domain2.com and carry over those search engine metrics. This is NOT THE CASE with the Canonical URL tag, which operates exclusively on a single root domain (it will carry over across subfolders and subdomains).
How, When & Where Should SEOs Use This Tag?
In the past, many sites have encountered issues with multiple versions of the same content on different URLs. This creates three big problems:
- Search engines don't know which version(s) to include/exclude from their indices
- Search engines don't know whether to direct the link metrics (trust, authority, anchor text, link juice, etc.) to one page, or keep it separated between multiple versions
- Search engines don't know which version(s) to rank for query results



What Information Have the Engines Provided About the Canonical URL Tag?
Quite a bit, actually. Check out a few important quotes from Google:
Is rel="canonical" a hint or a directive?from Yahoo!:
It's a hint that we honor strongly. We'll take your preference into account, in conjunction with other signals, when calculating the most relevant page to display in search results.
Can I use a relative path to specify the canonical, such as <link rel="canonical" href="product.php?item=swedish-fish" />?
Yes, relative paths are recognized as expected with the <link> tag. Also, if you include a <base> link in your document, relative paths will resolve according to the base URL.
Is it okay if the canonical is not an exact duplicate of the content?
We allow slight differences, e.g., in the sort order of a table of products. We also recognize that we may crawl the canonical and the duplicate pages at different points in time, so we may occasionally see different versions of your content. All of that is okay with us.
What if the rel="canonical" returns a 404?
We'll continue to index your content and use a heuristic to find a canonical, but we recommend that you specify existent URLs as canonicals.
What if the rel="canonical" hasn't yet been indexed?
Like all public content on the web, we strive to discover and crawl a designated canonical URL quickly. As soon as we index it, we'll immediately reconsider the rel="canonical" hint.
Can rel="canonical" be a redirect?
Yes, you can specify a URL that redirects as a canonical URL. Google will then process the redirect as usual and try to index it.
What if I have contradictory rel="canonical" designations?
Our algorithm is lenient: We can follow canonical chains, but we strongly recommend that you update links to point to a single canonical page to ensure optimal canonicalization results.
• The URL paths in the <link> tag can be absolute or relative, though we recommend using absolute paths to avoid any chance of errors.and from Live/MSN:
• A <link> tag can only point to a canonical URL form within the same domain and not across domains. For example, a tag on http://test.example.com can point to a URL on http://www.example.com but not on http://yahoo.com or any other domain.
• The <link> tag will be treated similarly to a 301 redirect, in terms of transferring link references and other effects to the canonical form of the page.
• We will use the tag information as provided, but we’ll also use algorithmic mechanisms to avoid situations where we think the tag was not used as intended. For example, if the canonical form is non-existent, returns an error or a 404, or if the content on the source and target was substantially distinct and unique, the canonical link may be considered erroneous and deferred.
• The tag is transitive. That is, if URL A marks B as canonical, and B marks C as canonical, we’ll treat C as canonical for both A and B, though we will break infinite chains and other issues.
What Questions Still Linger?
- This tag will be interpreted as a hint by Live Search, not as a command. We'll evaluate this in the context of all the other information we know about the website and try and make the best determination of the canonical URL. This will help us handle any potential implementation errors or abuse of this tag.
- You can use relative or absolute URLs in the “href” attribute of the link tag.
- The page and the URL in the “href” attribute must be on the same domain. For example, if the page is found on “http://mysite.com/default.aspx”, and the ”href” attribute in the link tag points to “http://mysite2.com”, the tag will be invalid and ignored.
- However, the “href” attribute can point to a different subdomain. For example, if the page is found on “http://mysite.com/default.aspx” and the “href” attribute in the link tag points to “http://www.mysite.com”, the tag will be considered valid.
- Live Search expects to implement support for this feature sometime in the near future.
A few things remain somewhat murky around the Canonical URL tag's features and results. These include:
- The degree to which the tag will be trusted by the various engines - will it only work if the content is 100% duplicate 100% of the time? Is there some flexibility on the content differences? How much?
- Will this pass 100% of the link juice from a given page to another? More or less than a 301 redirect does now? Note that Google's official representative from the web spam team, Matt Cutts, said today that it passes link juice akin to a 301 redirect but also noted (when SEOmoz's own Gillian Muessig asked specifically) that "it loses no more juice than a 301," which suggests that there is some fractional loss when either of these are applied.
- The extent of the tag's application on non-English language versions of the engines. Will different levels of content/duplicate analysis and country/language-specific issues apply?
- Will the engines all treat this in precisely the same fashion? This seems unlikely, as they'd need to share content/link analysis algorithms to do that. Expect anecdotal (and possibly statistical) data in the future suggesting that there are disparities in interpretation between the engines.
- Yahoo! strongly recommends using absolute paths for this (and, although we've yet to implement it, SEOmoz does as well, based on potential pitfalls with relative URLs), but the other engines are more agnostic - we'll see what the standard recommendations become.
- Yahoo! also mentions the properties are transitive (which is great news for anyone who's had to do multiple URL re-architectures over time), but it's not clear if the other engines support this?
- Live/MSN appears to have not yet implemented support for the tag, so we'll see when they formally begin adoption.
- Are the engines OK with SEOs applying this for affiliate links to help re-route link juice? We'd heard at SMX East from a panel of engineers that using 301s for this was OK, so I'm assuming it is, but many SEOs are still skeptical as to whether the engines consider affiliate links as natural or not.
If you have more questions, concerns or experiences to share about the new URL Canonicalization tag, please do so in the comments. I'll do my best to round up any unsolved queries and get some answers directly in the near future.
Further Reading on this topic from SELand, SEJournal, Yahoo!, Live & Google.
p.s. The search engines didn't consult with SEOmoz on this prior to release (I know, I know; dream on Rand), so Linkscape's index doesn't yet support the tag, but will beginning in the near future. We'll also try to provide some stats around adoption levels across the web as we're able.
Source: http://www.seomoz.org/blog/canonical-url-tag-the-most-important-advancement-in-seo-practices-since-sitemaps
Learn about the Canonical Link Element in 5 minutes
<link rel="canonical" href="http://example.com/page.html"/>That tells search engines that the preferred location of this url (the “canonical” location, in search engine speak) is http://example.com/page.html instead of http://www.example.com/page.html?sid=asdf314159265 .
I also did a three-minute video with WebProNews after the announcement to describe the tag, and you can watch the canonical link element video for another way to learn about it. Watching the video is the easiest way to learn about this new element quickly.
The search engines have also posted about this new open standard. You can read a blog post or help center documentation from Google, Yahoo’s blog post, or Microsoft’s blog post.
Also exciting is that Joost de Valk has already produced several plug-ins. Joost made a canonical plug-in for WordPress, a plugin for e-commerce software package Magento, and also a plug-in for Drupal. I’d expect people to make plug-ins for other software packages pretty soon, or modify the software to use this link element in the core software.
Thanks to the folks at Yahoo (e.g. Priyank Garg and others) and Microsoft (e.g. Nathan Buggia and others) who built consensus to support this open standard. On the Google side, Joachim Kupke did all the implementation and indexing work to make this happen; thanks for the heavy lifting on this, Joachim. I want to send a special shout-out to Greg Grothaus as well. Although people had discussed similar ideas in the past, Greg was a catalyst at Google and his proposal really got the ball rolling on this idea; read more about it on his blog.
If you’re interested, you can see the slides I presented last week to announce this new element:
I’ll be happy to try to answer questions if you’ve got ‘em, or you can ask questions on the official Google webmaster blog. If you’re going to SES London this week, Google’s own Maile Ohye will be at SES London to answer questions as well.
Update: I had “value” instead of “href” in the link element. Serves me right for not double-checking, and thanks to the commenters who noticed!
Update, 2/23/2009: Ask just announced that they will support the canonical link element. That means all the major search engines will be supporting this tag, which is great news for site owners, developers, and webmasters. Yay!
Help test some next-generation infrastructure
Monday, August 10, 2009 at 4:14 PM
Webmaster Level: AllTo build a great web search engine, you need to:
- Crawl a large chunk of the web.
- Index the resulting pages and compute how reputable those pages are.
- Rank and return the most relevant pages for users' queries as quickly as possible.
Some parts of this system aren't completely finished yet, so we'd welcome feedback on any issues you see. We invite you to visit the web developer preview of Google's new infrastructure at http://www2.sandbox.google.com/ and try searches there.
Right now, we only want feedback on the differences between Google's current search results and our new system. We're also interested in higher-level feedback ("These types of sites seem to rank better or worse in the new system") in addition to "This specific site should or shouldn't rank for this query." Engineers will be reading the feedback, but we won't have the cycles to send replies.
Here's how to give us feedback: Do a search at http://www2.sandbox.google.com/ and look on the search results page for a link at the bottom of the page that says "Dissatisfied? Help us improve." Click on that link, type your feedback in the text box and then include the word caffeine somewhere in the text box. Thanks in advance for your feedback!
Update on August 11, 2009: [ If you have language or country specific feedback on our new system's search results, we're happy to hear from you. It's a little more difficult to obtain these results from the sandbox URL, though, because you'll need manually alter the query parameters.
You can change these two values appropriately:
hl = language
gl = country code
Examples:
German language in Germany: &hl=de&gl=de
http://www2.sandbox.google.com/search?hl=de&gl=de&q=alle+meine+entchen
Spanish language in Mexico: &hl=es&gl=mx
http://www2.sandbox.google.com/search?hl=es&gl=mx&q=de+colores
And please don't forget to add the word "caffeine" in the feedback text box. :) ]
Google Caffeine: A Detailed Test of the New Google

While the developer version is a pre-beta release, it's completely usable. Thus, we've decided to put the new Google search through the wringer. We took the developer version for a spin and compared it to not only the current version of Google Search, but to Bing as well.
The categories we tested the new search engine on are as follows: speed, accuracy, temporal relevancy, and index size. Here's how we define those:
Speed: How fast can the new search engine load results?So without further ado, here's the test:
Accuracy: Which set of results is more accurate to the search term?
Temporal Relevancy: Is one version of search better at capturing breaking news?
Index Size: Is it really more comprehensive than the last version of Google?
1. Speed
The first category is incredibly important. How fast do these Google search results come at you anyway? Even a tenth of a second can mean millions for the search company as the longer it takes the load, the more likely someone will go look for results somewhere else.So how fast is the new search? Lightning fast. As you probably know, Google tells you how long it takes to load results. We tried a few search terms, starting with "Dog." Here's the speed result:


The only potential weak spot was when we added search commands like quotes, subtraction signs, and more. In this case, it was a 50/50 shot as to which Google search was faster.
As for comparing it to Bing: Well, they don't display how fast it generates results. It'll have to sit out this speed test for now.
Winner: The New Google
2. Accuracy
While more subjective, accuracy is probably the issue that users care about most. Does the search engine find what you want on the first try? Well, we did our subjective test. New version:

Both sets are very accurate, but subjectively, the set displayed by the new Google search more accurately reflect what a user would be looking for. If you're wondering about Bing, it didn't even bring up my personal website.
The next search, "Are social media jobs here to stay?" focused on getting my first Mashable article. The result? The new search cares more about keywords than the last. You could clearly see it cared about the full title and brought up more results with those keywords. Both brought a different set of results, but the new search was more relevant.
Winner: The New Google (tentatively)
3. Temporal Relevancy
How good is each at breaking news? The answer: about the same. FriendFeed results were identical, including the top news items. Searches for "Hall of Fame Game" got better news results on the new search. A search for "China Landslide" also got the same Yahoo and BBC news articles - although we did notice that the new search seems to change faster with new articles. It put an MSNBC article up high for updating the death toll:
Winner: Draw
4. Index Size:
Perhaps the easiest to test, we can tell the index size based on how many results come up for specific search. Here are searches once again for "dog:"New:

Winner: Bing, it seems
Conclusion
While this test was nowhere near scientific, we do have some solid takeaways:New Google is FAST: It often doubled the speed of Google classic.The new Google will only get better as features are implemented and developed. The end result is a better search experience for the user. Competition really does breed innovation.
New Google relies more on keywords: SEO professionals, your job just got a lot harder. The algorithm's definitely different. It has more reliance on keyword strings to produce better results.
Search is moving into real-time: Being able to get info on breaking events is clearly a priority for Google and Bing. With both Twitter and Facebook launching real-time search engines, they needed to respond.
It's partially a response to Bing: At least, that's how we feel. This new search has a focus on increasing speed, relevancy, accuracy, and the index volume, things that Microsoft really hit on when it released Bing. It feels as if Google "Caffeine" is meant to shore up any deficiencies it may have when compared to Microsoft's offering, though it's been in the works long before Bing launched.
Google Launches Real Time Search Results
Dec 7, 2009 at 2:56pm ET by Danny Sullivan
So finally, we’ve got Google Real Time search, as the company has announced.
Below, I’m doing a quick hit on what’s it is, how to use it and how it
compares to that last Google real time search thing you may recall
hearing about.
How do you get it? It’s rolling out over the next few days, and when you have it, you’ll see it just happening withing your search results. But if you can’t see it, try clicking on this link which may force it to appear for you.
For example, below is a search for health care on Google where about midway down on the page, there’s a “Latest results” section that appears with real time results:
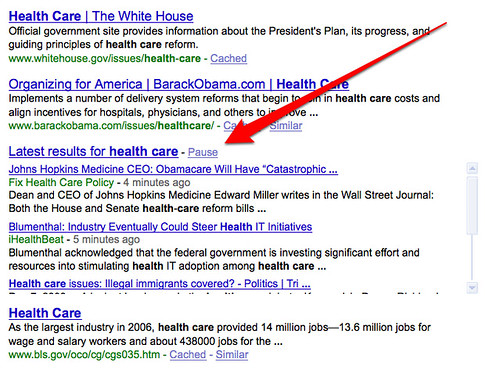
The results automatically flow with new information — and if that’s annoying, you can use the “Pause” link at the top of the section to stop them. What you can’t do is remove the section entirely, if you don’t like it.
By the way, you won’t always see the results. “If high quality information is coming in, then we will show it,” said Amit Singhal, a Google fellow who heads Google’s ranking systems and oversaw the development of the new real time search system, when I talked with him after the Google press conference.
In other words, if Google thinks something has some real-time component to it, then it will show the section. In particular, if Google sees a spike in information on a certain topic, along with queries on a particular topic, then it assumes there’s a real time situation happening — very simplified!
Click on the Latest results link, and you can drill down into the results:
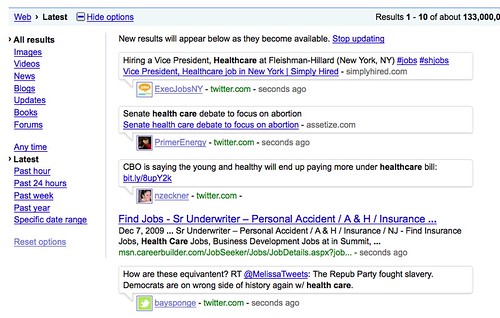
What do you get? Singhal said:
Google previously announced a deal with Twitter to take in its data. Bing has one too. Bing also has a Facebook deal for data, though it has yet to implement that data into search. Part of today’s news was that Google now has a Facebook deal plus one with MySpace, which Bing doesn’t have.
Google wouldn’t release any financial details about any of these deals. It wouldn’t even confirm if there ARE financial deals. For all we know, Google’s getting the information from Twitter, Facebook and MySpace for free. I believe Twitter’s suggested it is being paid from Google and Bing for its data (I’m checking on this). I believe Facebook has said there’s no financial arrangement between it and Bing for its data (again, checking on this).
MySpace is a particularly interesting situation. Rupert Murdoch’s News Corporation owns MySpace. Murdoch wants Google to pay for News Corp’s content. So when it comes to MySpace, is Murdoch getting paid for data there but not for Google News? Or is he happy to give that data away for free but not when it comes to news?
I haven’t had time to drill into the relevancy of what’s presented and compare it against places like Twitter Search or other real time meta services like Collecta.
How the information ranked? Singhal said only information deemed highly relevant is included. So spammy tweets, low quality pages and other content might not make it into the real time search “layer” that is used. After that, results are ranked by time.
How about ranking content in other ways. For example, if searching on a particular topic, does it make sense to show the most “authoritative” tweet first, rather than giving primacy to the latest ones?
“I would not be surprised if you start seeing far more of an emphasis on original tweets in our search,” Singhal said.
If you look at the second screenshot above, you’ll see that the “Latest” option in Google’s Search Options pane is flagged. Now look further up, and you’ll see that this is for “All Results” that Google has (or what’s called “Everything” results in the new Googel web search user interface being tested).

Under all results, there’s a new “Updates” option that can be toggled. So want to see the “latest” or real-time results that are only status updates (such as tweets?). Toggle the Updates option, and you’ll filter out other things like real-time news reports or new web pages that are added.
I like this feature, because to me, “real time search” means bringing back microblogged content, not news results, not freshly updated web pages and so on. For the detailed explanation about that, see my What Is Real Time Search? Definitions & Players post.
That post also explains a class of “real time” search that Google is not doing, such as allowing you to explore the most popular links that are being tweeted. The folks at some places like OneRiot can thus breathe a sigh of relief. Even Bing’s Twitter search retains some bragging rights.
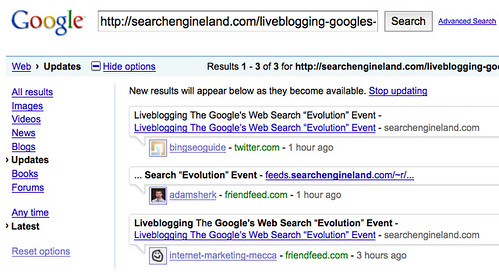
Enter a URL into Google’s real time search service, and you don’t see much about what’s related to it in terms of real time commentary. For example, here’s what’s shown when I searched for information related to my live blogging of today’s Google news:
Do the same for Bing’s Twitter search, and you get much more content:
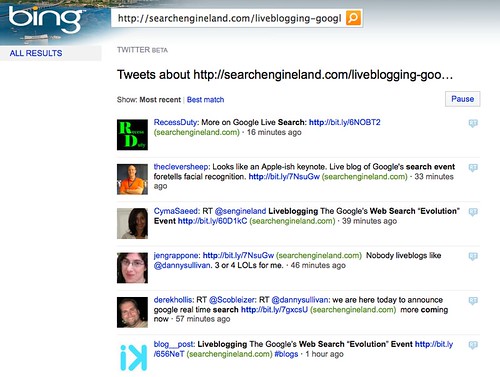
This may change, by the way. Google said that it be growing its real time search service over time, so watch and see. Also see Up Close With Bing’s Twitter Search Engine for more about Bing’s service.
Google also noted that it is expanding shortened URLs. You’ll still see the shortened version listed (say if it is from bit.ly or another URL shortener), but then you’ll also see the final destination URL. Content from that destination page is spidered.
Related to Google real time search is a new real times trends feature on Google Trends, which itself officially comes out of Google Labs today. Let’s do a screenshot:
On the right is what Google Trends had before, topics that are deemed popular based on searches entered into Google. By popular, these are things that are seen as out of the ordinary. Otherwise, you’d see queries like “sex” and “hotmail” always showing up.
On the left is what’s new, top trends based on Google’s analysis of real time content. This is important. The trends you see at Twitter, on its home page if you’re logged out, are based to my knowledge on what people are searching for on Twitter:
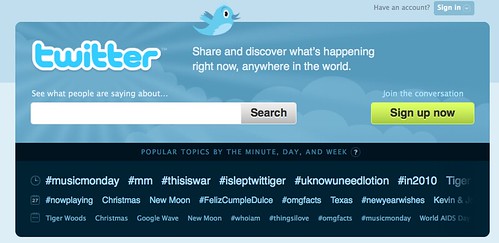
In contrast, Google’s real time trends — “Hot Topics” — are based on what it sees from analyzing the text of real time content.
I can’t say if one method is better than another. Both probably have advantages.
Below the Hot Topics list is a search box that effectively provides a front-end to Google real time search. Enter a search query, such as climategate, and you’ll get back matching real time results.
Currently, Google says there’s no plans for a dedicated standalone real time search page as you get for say Google News or Google Images. However, I can point you to a pseudo-page like this. Go here, and you’ll get a nice clean Google home page that is configured to search for real time information.
And how about real time search and its importance to Google overall? Was this really a major gap that could have killed the company?
Hardly, in my view. There’s no doubt that it’s good to have. It’s incredibly difficult to be a leading information source and yet when there’s an earthquake, people are instead turning to Twitter for confirmation faster than traditional news sources on Google can provide.
Google vice president of search products and user experience Marissa Mayer gave me a personal example of how having real time data can help Google. An avid skier, she found herself going to Twitter on a regular basis to get ski reports from people actually on the slopes, which she found more accurate than what some resorts and other reporting services were offering.
Google could have survived without a real time search component — in particular without the dedicated flow of microblogged updates — but it becomes a more complete and useful service with them. I’m glad to see the integration and am looking forward to see how it matures.
Still, in the long term for those trying to measure the search face-off between Google and Bing, it’s not real time search that’s the major battlefield. Instead, it’s personalized search that I think is far more important. And on Friday, Google unveiled with far less fanfare a major change in how it provides personalized results. For more on that, see:
Our Google Social Search Launches, Gives Results From Your Trusted “Social Circle” article covers that system and how it works in more detail. It’s completely separate from real time search. In fact, potentially you could do a search and get a section with real time results on the same page as results from your social network.


How do you get it? It’s rolling out over the next few days, and when you have it, you’ll see it just happening withing your search results. But if you can’t see it, try clicking on this link which may force it to appear for you.
For example, below is a search for health care on Google where about midway down on the page, there’s a “Latest results” section that appears with real time results:
The results automatically flow with new information — and if that’s annoying, you can use the “Pause” link at the top of the section to stop them. What you can’t do is remove the section entirely, if you don’t like it.
By the way, you won’t always see the results. “If high quality information is coming in, then we will show it,” said Amit Singhal, a Google fellow who heads Google’s ranking systems and oversaw the development of the new real time search system, when I talked with him after the Google press conference.
In other words, if Google thinks something has some real-time component to it, then it will show the section. In particular, if Google sees a spike in information on a certain topic, along with queries on a particular topic, then it assumes there’s a real time situation happening — very simplified!
Click on the Latest results link, and you can drill down into the results:
What do you get? Singhal said:
- Tweets from Twitter
- Content from Google News
- Content from Google Blog Search
- Newly created web pages
- Freshly updated web pages
- FriendFeed update
- Jaiku updates
- Identi.ca updates
- TwitArmy updates
Google previously announced a deal with Twitter to take in its data. Bing has one too. Bing also has a Facebook deal for data, though it has yet to implement that data into search. Part of today’s news was that Google now has a Facebook deal plus one with MySpace, which Bing doesn’t have.
Google wouldn’t release any financial details about any of these deals. It wouldn’t even confirm if there ARE financial deals. For all we know, Google’s getting the information from Twitter, Facebook and MySpace for free. I believe Twitter’s suggested it is being paid from Google and Bing for its data (I’m checking on this). I believe Facebook has said there’s no financial arrangement between it and Bing for its data (again, checking on this).
MySpace is a particularly interesting situation. Rupert Murdoch’s News Corporation owns MySpace. Murdoch wants Google to pay for News Corp’s content. So when it comes to MySpace, is Murdoch getting paid for data there but not for Google News? Or is he happy to give that data away for free but not when it comes to news?
I haven’t had time to drill into the relevancy of what’s presented and compare it against places like Twitter Search or other real time meta services like Collecta.
How the information ranked? Singhal said only information deemed highly relevant is included. So spammy tweets, low quality pages and other content might not make it into the real time search “layer” that is used. After that, results are ranked by time.
How about ranking content in other ways. For example, if searching on a particular topic, does it make sense to show the most “authoritative” tweet first, rather than giving primacy to the latest ones?
“I would not be surprised if you start seeing far more of an emphasis on original tweets in our search,” Singhal said.
If you look at the second screenshot above, you’ll see that the “Latest” option in Google’s Search Options pane is flagged. Now look further up, and you’ll see that this is for “All Results” that Google has (or what’s called “Everything” results in the new Googel web search user interface being tested).
Under all results, there’s a new “Updates” option that can be toggled. So want to see the “latest” or real-time results that are only status updates (such as tweets?). Toggle the Updates option, and you’ll filter out other things like real-time news reports or new web pages that are added.
I like this feature, because to me, “real time search” means bringing back microblogged content, not news results, not freshly updated web pages and so on. For the detailed explanation about that, see my What Is Real Time Search? Definitions & Players post.
That post also explains a class of “real time” search that Google is not doing, such as allowing you to explore the most popular links that are being tweeted. The folks at some places like OneRiot can thus breathe a sigh of relief. Even Bing’s Twitter search retains some bragging rights.
Enter a URL into Google’s real time search service, and you don’t see much about what’s related to it in terms of real time commentary. For example, here’s what’s shown when I searched for information related to my live blogging of today’s Google news:
Do the same for Bing’s Twitter search, and you get much more content:
This may change, by the way. Google said that it be growing its real time search service over time, so watch and see. Also see Up Close With Bing’s Twitter Search Engine for more about Bing’s service.
Google also noted that it is expanding shortened URLs. You’ll still see the shortened version listed (say if it is from bit.ly or another URL shortener), but then you’ll also see the final destination URL. Content from that destination page is spidered.
Related to Google real time search is a new real times trends feature on Google Trends, which itself officially comes out of Google Labs today. Let’s do a screenshot:
On the right is what Google Trends had before, topics that are deemed popular based on searches entered into Google. By popular, these are things that are seen as out of the ordinary. Otherwise, you’d see queries like “sex” and “hotmail” always showing up.
On the left is what’s new, top trends based on Google’s analysis of real time content. This is important. The trends you see at Twitter, on its home page if you’re logged out, are based to my knowledge on what people are searching for on Twitter:
In contrast, Google’s real time trends — “Hot Topics” — are based on what it sees from analyzing the text of real time content.
I can’t say if one method is better than another. Both probably have advantages.
Below the Hot Topics list is a search box that effectively provides a front-end to Google real time search. Enter a search query, such as climategate, and you’ll get back matching real time results.
Currently, Google says there’s no plans for a dedicated standalone real time search page as you get for say Google News or Google Images. However, I can point you to a pseudo-page like this. Go here, and you’ll get a nice clean Google home page that is configured to search for real time information.
And how about real time search and its importance to Google overall? Was this really a major gap that could have killed the company?
Hardly, in my view. There’s no doubt that it’s good to have. It’s incredibly difficult to be a leading information source and yet when there’s an earthquake, people are instead turning to Twitter for confirmation faster than traditional news sources on Google can provide.
Google vice president of search products and user experience Marissa Mayer gave me a personal example of how having real time data can help Google. An avid skier, she found herself going to Twitter on a regular basis to get ski reports from people actually on the slopes, which she found more accurate than what some resorts and other reporting services were offering.
Google could have survived without a real time search component — in particular without the dedicated flow of microblogged updates — but it becomes a more complete and useful service with them. I’m glad to see the integration and am looking forward to see how it matures.
Still, in the long term for those trying to measure the search face-off between Google and Bing, it’s not real time search that’s the major battlefield. Instead, it’s personalized search that I think is far more important. And on Friday, Google unveiled with far less fanfare a major change in how it provides personalized results. For more on that, see:
- Google Now Personalizes Everyone’s Search Results
- Google’s Personalized Results: The “New Normal” That Deserves Extraordinary Attention
Our Google Social Search Launches, Gives Results From Your Trusted “Social Circle” article covers that system and how it works in more detail. It’s completely separate from real time search. In fact, potentially you could do a search and get a section with real time results on the same page as results from your social network.
SearchCap:
Get all the top search stories emailed daily!Like Our Site? Follow Us!
Read before commenting! We welcome constructive
comments and allow any that meet our common sense criteria. This means
being respectful and polite to others. It means providing helpful
information that contributes to a story or discussion. It means leaving
links only that substantially add further to a discussion. Comments
using foul language, being disrespectful to others or otherwise
violating what we believe are common sense standards of discussion will
be deleted. Comments may also be removed if they are posted from anonymous accounts. You can read more about our comments policy here.
Did you know you can create short urls with AdFly and get $$$ for every visitor to your shortened links.
ReplyDeleteGet Paid On Social Media Sites?
ReplyDeleteView Social Media Jobs from the comfort of home!